协程
协程又被成为纤程、微线程、用户态线程。与线程相比而言,它是 CPU 无法感知到的,CPU 调度依然以线程为最小单位。协程的根本革命性在于:
以同步的方式完成了异步编程
协程之间无需加锁
协程有两种用途,一种是用作一般的控制流转移,例如 Python 的生成器。而另一种是在执行某些 IO 繁忙的操作时让出协程,去执行其它函数。之所以是 IO 繁忙是因为等待外设就绪的这部分时间对程序来说是无工作的。
协程分类
对称协程和非对称协程
根据控制转移机制可以将协程分为对称协程和非对称协程。对称协程有无调度器,需要程序员手动调度协程,而非对称协程则有调度器,程序会在 恰当 的时候主动让出协程。
boost.coroutine2 就是非对称协程,而 boost.fiber 就是对称协程,在使用 boost.fiber 提供的 barrier, mutex 等工具时,会引起协程调度。
有栈协程和无栈协程
有栈协程和无栈协程实际上运行时都是有栈的,但是有栈协程会在堆上分配空间用作协程栈来保存上下文信息,而无栈协程则直接使用系统栈。有栈协程由于保存了自己的上下文信息,因此允许在任意嵌套深度的环境下进行协程切换操作。而无栈协程只允许在非嵌套环境下使用。(比如不能在 Lambda 表达式中切换)
另外,有栈协程又分为共享栈和非共享栈,其中的区别是堆上分配的空间是否被协程之间共享使用。共享栈能够降低协程的内存开销,但是非共享栈实现简单,效率也高。
提示
相较于有栈协程的百花齐放,无栈协程的实现相对有限。知名的仅有 Protothreads 一个。另外,C++ 20 中引入的协程也是无栈协程
调用栈
函数调用栈是一段连续的地址空间,无论 caller 还是 callee 都位于这段空间内。调用栈中一个函数所占用的空间称为一个栈桢,调用栈就是由若干栈桢拼接成的,一个典型的调用栈为:
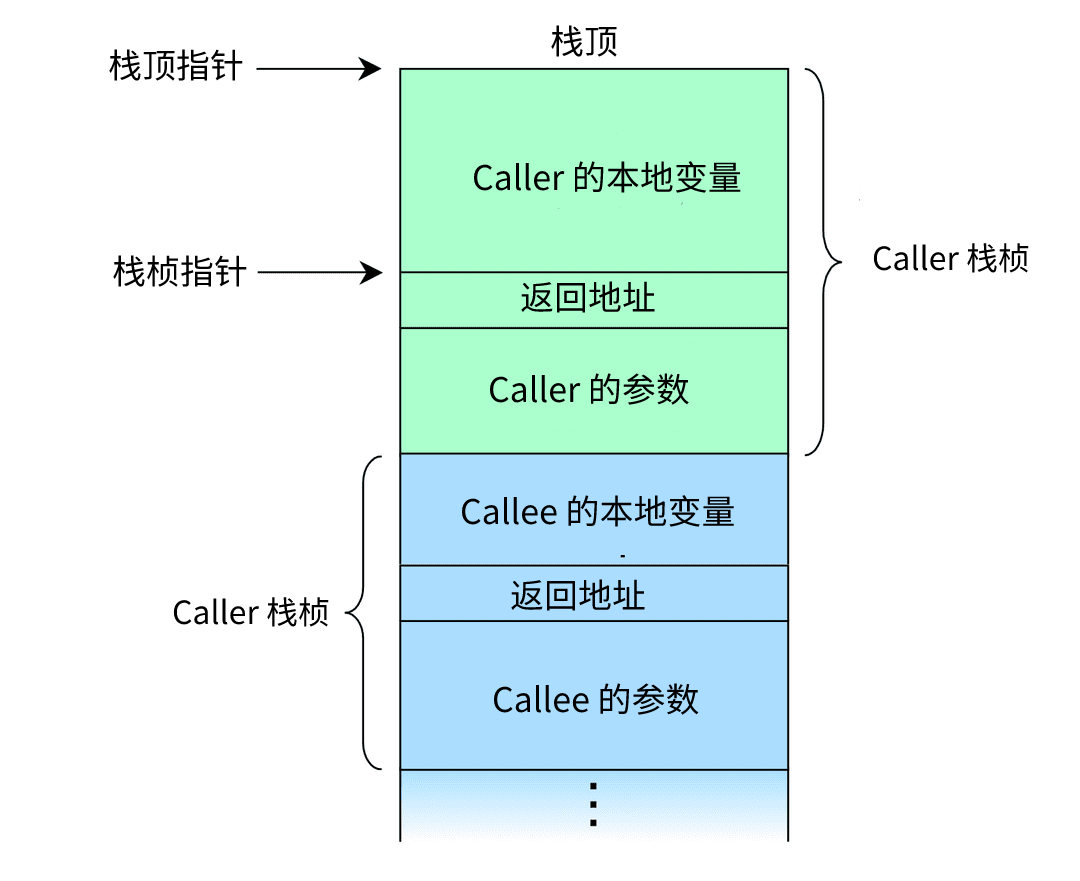
其中, 栈顶指针 总是指向调用栈的顶部地址,此地址由 esp 寄存器储存。 栈桢指针 实际上就是基址指针,由 ebp 储存。 返回地址 储存的是在 callee 返回后 caller 需要继续执行的地址。
备注
调用栈和广义意义上程序的栈并无太大区别。一般来说调用栈是程序栈的组成部分,但是对于有栈协程,很多时候是在堆中分配内存,然后将此内存指定为调用栈。这时候调用栈就存在于堆中,而不是系统栈上。调用栈分配过小可能会导致 SIGBUS 错误
协程原语
协程有两个基本原语:yield 用于让出,resume 用于恢复
yield 和 resume 都是由 switch 实现的,switch 的两步功能为:
switch(from, to)
save from.ctx
load to.ctx
switch 实现有三种方式:
ucontext
setjmp/longjmp
使用汇编
粘合 CPU 是计算密集型
协程的实现方式
协程有三种实现方式:
使用汇编完成上下文切换
使用 ucontext 库
使用 setlongjump
一些不错的实现为:
库 |
实现方式 |
|---|---|
ucontext |
|
汇编 |
协程
首先要明白协程的本质是什么。实际上协程就是一个用户态的函数,而协程的切换需要完成的工作就是在函数之间进行切换。
寄存器组是唯一被所有过程共享的资源,根据约定,rbx, rbp, r12-r15 是 被调用者保存 寄存器,这意味着当过程 P 调用过程 Q 时,过程 Q 负责保存这些寄存器 。除了 rsp,剩下的寄存器被称为 调用者保存 寄存器,这意味着当过程 P 调用 Q 时,保存这些寄存器是过程 P 的责任。
x64 的 CPU 一共有 16 个通用寄存器,但是我们只需要其中的 10 个就行,这 10 个寄存器分别是:
rax |
返回值 |
|---|---|
rbx |
被调用者保存 |
rcx |
第 4 个参数 |
rdx |
第 3 个参数 |
rsi |
第 2 个参数 |
rdi |
第 1 个参数 |
rbp |
被调用者保存 |
rsp |
栈指针 |
r8 |
第 5 个参数 |
r9 |
第 6 个参数 |
r10 |
调用者保存 |
r11 |
调用者保存 |
r12 |
被调用者保存 |
r13 |
被调用者保存 |
r14 |
被调用者保存 |
r15 |
被调用者保存 |
还有一个特殊寄存器 rip 用来保存 CPU 下一个执行的指令。根据上面的约定,我们只需要保存 rbx, rsi, rdi, rbp, rsp, rip, r12, r13, r14, r15 这 9 个寄存器
备注
rbp 的作用是作为 rsp 的备份。这样当 rsp 前进时,局部变量和函数参数可以相对于 rbp 访问 c - What is the purpose of the RBP register in x86_64 assembler?
x64 的调用约定都准许 System V ABI 规范。但是 Linux 和 Windows 对于函数参数的处理略有不同 GCC的调用约定
使用 ucontext 实现的协程
下面讲述使用 ucontext 实现协程的方法和原理
ucontext
注
代码实现位于仓库:https://github.com/cathaysia/CoCo
ucontext 使用结构体 ucontext_t 来保存上下文信息,其定义可以简化为:
typedef struct {
void *ss_sp; // 栈顶
int ss_flags; // 栈标志
size_t ss_size; // 栈大小
} stack_t;
typedef struct {
...
struct ucontext_t *uc_link; // 指向后继上下文
stack_t uc_stack; // 协程栈
...
} ucontext_t;
而操纵上下文的几个函数分别为:
int getcontext(ucontext_t *ucp); // 将当前上下文保存到 ucp 中
int setcontext(const ucontext_t *ucp); // 设置当前上下文
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...); // 为 ucp 设置栈空并将 func 设置为 ucp 的后继上下文
int swapcontext(ucontext_t *oucp, ucontext_t *ucp); // 将当前上下文保存到 oucp 中,然后切换到 ucp 上
所谓的 后继上下文 就是指在当前上下文执行完毕后切换到后继上下文上。如果后继上下文为空指针,则推出线程
另外,makecontext 函数使用前 ucp 必须已经使用 getcontext 进行了初始化
一个初始化上下文的代码为:
getcontext(&ctx_); // 使用当前上下文初始化 ctx_
// 设置上下文的栈属性
ctx_.uc_stack.ss_sp = stack_;
ctx_.uc_stack.ss_size = kSTACK_SZIE;
ctx_.uc_stack.ss_flags = 0;
ctx_.uc_link = &(Schedule::getInstance()->main_);
// 使用 ucontext 的成员函数初始化实际上下文对象
makecontext(&ctx_, &Schedule::mainCo, 0);
协程库的基本结构
就像线程分为主线程和分线程一样,协程也分为主协程和普通协程,两者的区别在于主协程只负责对普通协程的调度,而普通协程则是工作协程。两者除了职责不同外其余完全相同。
协程完整的实现为:
constexpr const int kSTACK_SZIE = 1024 * 128; // 协程栈的大小,不能在小了
struct Coroutine {
enum State { Stopped, Ready, Running, Suspend };
State state_;
CoFun func_;
void *args_;
char stack_[kSTACK_SZIE];
ucontext_t ctx_;
Coroutine(CoFun func, void *args) : state_(Coroutine::Ready), func_(func), args_(args), stack_ { 0 } {
getcontext(&ctx_);
ctx_.uc_stack.ss_sp = stack_;
ctx_.uc_stack.ss_size = kSTACK_SZIE;
ctx_.uc_stack.ss_flags = 0;
ctx_.uc_link = &(Schedule::getInstance()->main_);
makecontext(&ctx_, &Schedule::mainCo, 0);
}
Coroutine(Coroutine const &) = delete;
};
主协程被放置在调度器中,一个调度器包含了主协程的上下文对象 main_ 和主协程需要执行的函数 mainCo。
当普通协程执行完毕后会自动切换到主协程上下文 main_ 并开始执行主协程的函数 mainCo
调度器的声明为:
using cid = int;
using CoFun = void (*)(Schedule *s, void *args);
struct Schedule {
ucontext_t main_; // 主协程 上下文
int cur_co_; // 当前正在执行的协程的 id 号
std::deque<Coroutine *> coroutines_; // 用户协程队列
static Schedule *getInstance(); // 获取调度器
static void mainCo(); // 主协程的调度函数
cid push(CoFun fun, void *args); // 根据 fun 和 args 创建协程并将其储存到 coroutines_ 中
bool finished(); // 判读是否所有协程已经终止
void run(cid id); // 执行一个协程
Coroutine::State state(cid id); // 查看 cid 为 id 的协程的状态
Schedule(Schedule const&) = delete; // 禁止拷贝对象
~Schedule();
private:
Schedule() = default;
};
和线程有 tid 一样,我们也为协程声明了一个新的类型 cid。我们不将 cid 储存在协程对象中,这是因为:
在协程执行时其 cid 总是等于 Schedule::cur_co_
当协程终止后我们可以重复利用它的 id 号
现在,我可以描述整个函数的流程:
整个流程如图所示。
代码如下:
Schedule *s = Schedule::getInstance();
cid id1 = s->push(func1, args1);
cid id2 = s->push(func2, args2);
while(!s->finished()) {
for(int i = 0; i < s->coroutines_.size(); ++i) {
switch(s->coroutines_[i]->state_) {
case Coroutine::Ready: s->run(i); break;
case Coroutine::Suspend: resume(i); break;
default: break;
}
}
}
创建调度器
调度器我们一个线程一个调度器,线程之间不共享:
Schedule *Schedule::getInstance() {
thread_local static Schedule *s = nullptr;
if(s) return s;
s = new Schedule;
s->cur_co_ = -1;
return s;
}
另外,函数 mainCo 会在协程第一个被运行前调用,其根据调用当前活跃协程的函数:
void Schedule::mainCo() {
Schedule *s = Schedule::getInstance();
if(s->cur_co_ == -1) return;
Coroutine *c = s->coroutines_[s->cur_co_];
c->func_(s, c->args_);
c->state_ = Coroutine::Stopped;
s->cur_co_ = -1;
}
创建协程
我们先查找已经结束的协程的 cid,然后复用其 cid,否者创建一个新协程:
cid Schedule::push(CoFun func, void *args) {
int i = 0;
for(i = 0; i < coroutines_.size(); i++) {
if(coroutines_[i]->state_ == Coroutine::Stopped) {
delete coroutines_[i];
Coroutine *c = new Coroutine(func, args);
coroutines_[i] = c;
break;
}
}
if(i == coroutines_.size()) {
Coroutine *c = new Coroutine(func, args);
coroutines_.push_back(c);
}
return i;
}
让出协程和恢复协程
这一步骤只是简单地在主协程和普通协程之间进行切换:
void yield() {
Schedule *s = Schedule::getInstance();
if(s->cur_co_ == -1) return;
Coroutine *c = s->coroutines_[s->cur_co_];
c->state_ = Coroutine::Suspend;
s->cur_co_ = -1;
swapcontext(&(c->ctx_), &(s->main_));
}
void resume(cid id) {
Schedule *s = Schedule::getInstance();
if(id < 0 || id > s->coroutines_.size()) return;
Coroutine *c = s->coroutines_[id];
if(c && c->state_ == Coroutine::Suspend) {
c->state_ = Coroutine::Running;
s->cur_co_ = id;
swapcontext(&(s->main_), &(c->ctx_));
}
}